Background

A large organization operates across the globe, with offices in a dozen countries. Business is good, but users in remote branch offices - especially in East Asia and North Africa - complain about severe performance problems with the new inventory management platform.
The IT group, located in the corporate headquarters in North America, can't replicate the alleged performance problems; furthermore, systems and network monitoring dashboards consistently report great performance metrics. Complaints from remote branches are therefore labeled as PICNIC and no further action is taken.
The problem, however, doesn't go away. Things escalate, and within a matter of weeks, regional Vice-Presidents start a coordinated campaign to decentralize IT. Pressure on corporate executives increases. Eager to appease the troops, the CTO himself jumps on a corporate jet and flies to the most important branch office in East Asia, where he witnesses firsthand the performance problems. Less than 24h later, a corporate IT task force is assembled to address the problem.
The perfect storm
As we get involved with the task force, we quickly determine that the performance problems experienced by remote users are the results of a perfect storm made of four contributing factors.
Factor #1: the WAN architecture
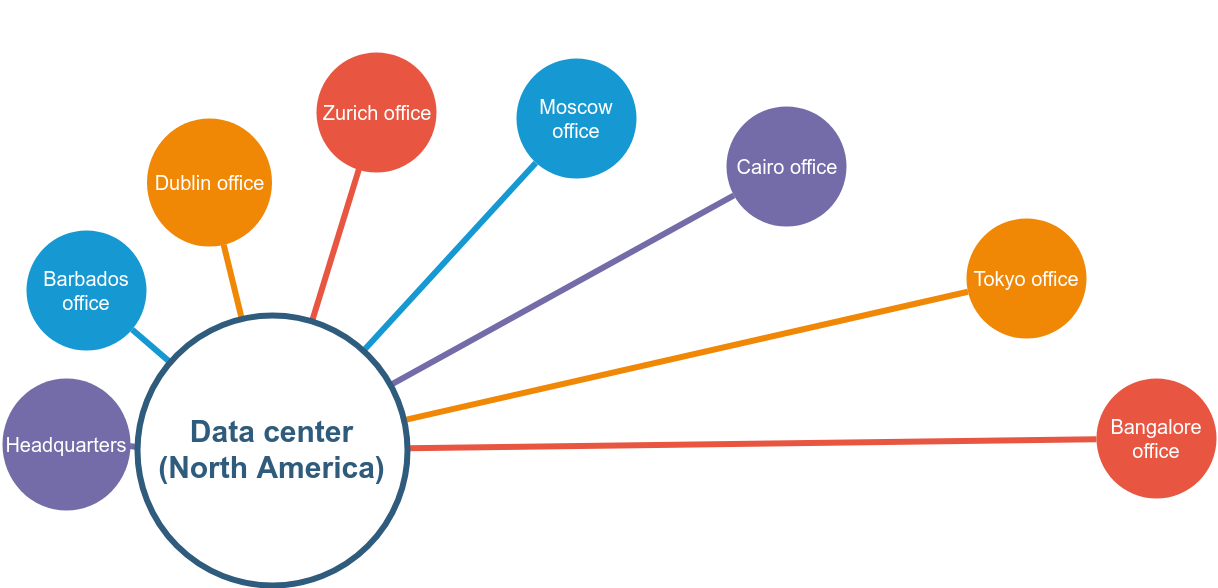
Besides laptops, printers and internet access, there is no local computing infrastructure in regional offices. Everything, including the new inventory management platform, is hosted in a data center located in the basement of the corporate headquarters in North America. Regional offices are connected to the data center via a WAN link, leased at great cost from a telecom provider.
The IT group is aware that the WAN architecture is a liability for the organization and has been diligently working on a migration to cloud computing, but this is an ambitious project with multiple technical hurdles, and production workloads are not expected to run in the cloud for at least another year.
Factor #2: limited monitoring capabilities
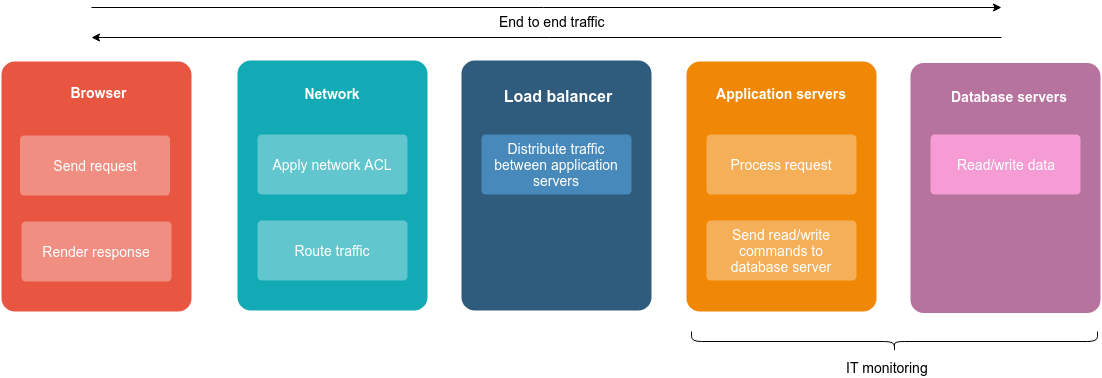
Users interact with the inventory management platform via a web interface. What appears as a simple web page in a browser is only the tip of a fairly complex iceberg, involving multiple layers that can contribute to a bad user experience.
Unfortunately, the monitoring system implemented by IT group only provides visibility on the backend nodes (the application servers and the database servers), providing them with metrics that may not reflect the actual behavior of the end-to-end application.
Factor #3: unpredictable WAN behavior
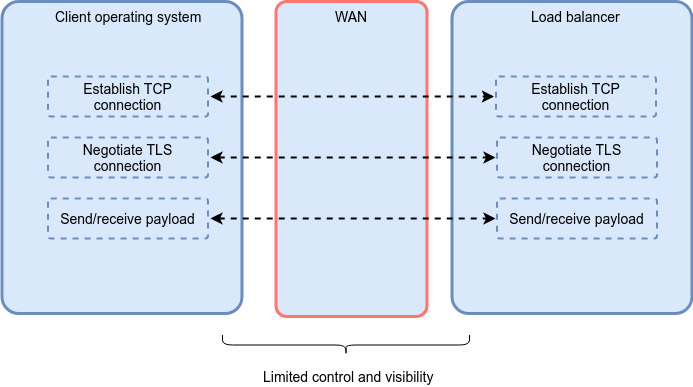
The WAN architecture implemented by the telecom provider relies on a routing technique called MPLS, built on top of a smorgasbord of network protocols and transport media.
When the link crosses multiple national boundaries and very large geographical distances, the odds of having small parts of the underlying array of networks misbehave increase significantly. Such blips, however, are invisible to typical network monitoring tools on the WAN side, which tend to aggregate performance metrics.
The only way to reliably document the WAN behavior is to perform a series of specialized tests, combining multiple measures (latency, bandwidth stability, etc.) and correlating them. We quickly implement those tests and provide raw data to the organization's analytics team, which identifies a slew of recurring bottlenecks within the MPLS mesh. We suspect that such bottlenecks are a symptom of bufferbloat, which is out of the IT group's control.
Factor #4: browser limitations
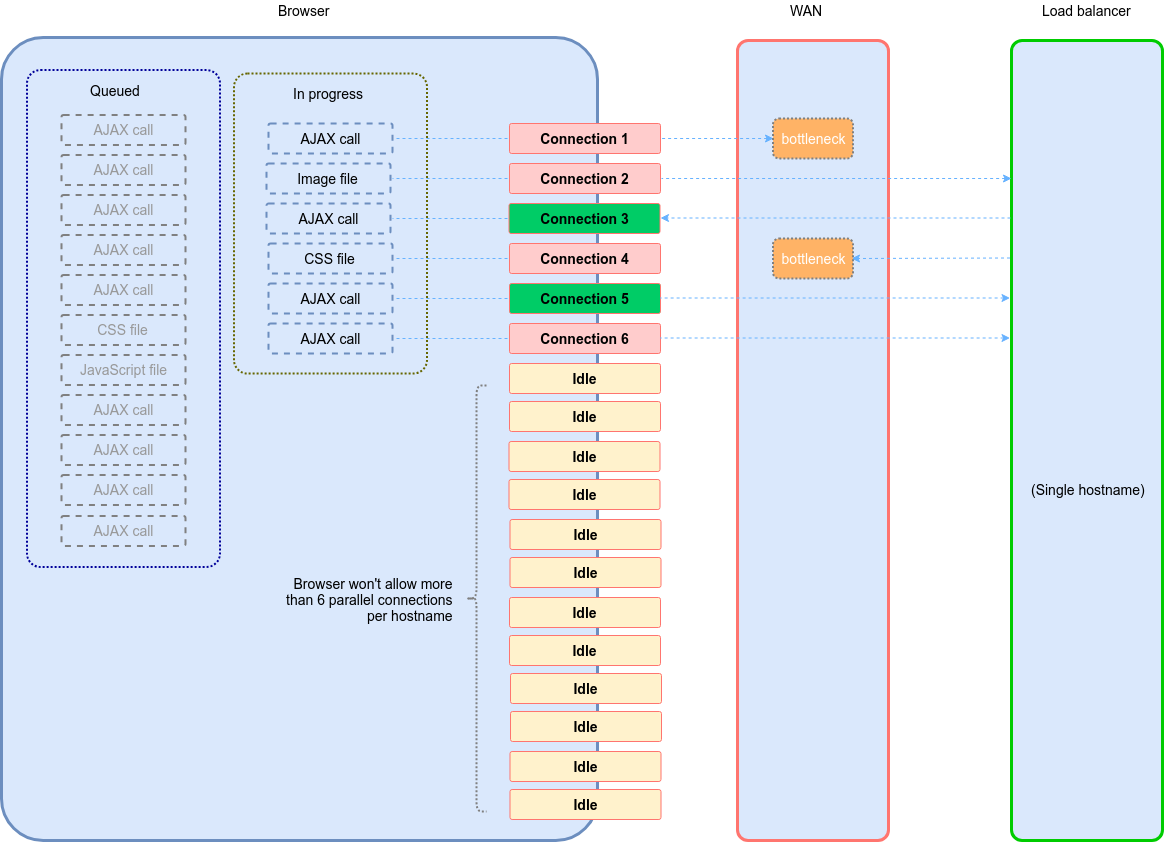
Modern web GUI such as the inventory management platform are typically single-page applications relying heavily on AJAX, which means that a constant flow of information takes place between the browser and the application server in response to user actions, without reloading the page. When everything works well, this design provides a smooth user experience. When network problems are present, the entire application gets sluggish and can appear buggy.
The problem is compounded when all the browser requests are directed to a single hostname, regardless of how many individual servers are involved in handling those requests. Browsers only allow a given number of parallel requests (usually between 15 and 20) at any time, of which no more than five or six can be directed to a same hostname. This is a great design that accounts for the nature of the modern Internet, where web pages are crammed with ads and various tracking mechanisms. Unfortunately, this means that a majority of the available parallel browser connections are idle if the entire web application is accessed thru a single hostname.
Just fix it!
Since the organization is already in the process of migrating their IT infrastructure to the cloud, the mandate of the task force is not to rearchitect the WAN or to redesign the inventory management platform. Senior management is looking for a stop-gap solution (a quick fix) to improve user experience in remote branches right away while a long-term solution is in the works.
We come up with a simple action plan designed to work around most of the technical issues:
- Since static content (such as images) doesn't change in response to user actions, we propose to host such content on a cloud-based CDN with endpoints located near each remote branch. Not only does this remove pressure on the busy WAN link, it also allows for a smoother user experience since faster rendering of static content does improve perceived performance in web applications. This solution also frees up browser connections quicker, allowing for a higher througput of AJAX calls.
- We create multiple virtual aliases on the load-balancer and configure the appliance to redirect heaviest AJAX calls to different hostnames. This increases the number of parallel requests initiated by the browsers, providing end users with a significant upgrade in terms of performance.
- We register multiple IP addresses per hostname in the corporate DNS, and lower the TTL of DNS resolutions. This prevents browser requests from being constantly directed to a same IP address, decreasing the chances of experiencing network bottlenecks on all connections.
Mission accomplished
The simple solutions implemented to work around network problems prove quite effective. While some blips are still experienced by users in remote offices, their overall experience improves a lot, which buys some time while the IT group works on the long-term cloud solution.