Background

The IT group in a rather large organization has adopted over the years a "best of breed" approach to enterprise architecture. Whenever a new need arises in the business, the best software package available on the market is acquired and implemented, regardless of how easily it can be integrated with the rest of the growingly complex software portfolio. The IT group believes that this approach has served the organization well and doesn't plan to change course.
To enable this constellation of products to interact smoothly, the organization relies on an aging enterprise application integration platform that is becoming difficult to operate. A decision is made to replace it with a top-of-the-line product thas offers a modern and flexible architecture (REST API, microservices-oriented, container-friendly).
The pilot phase goes well; the product works according to expectations. However, this new technology comes with a per-CPU licensing model that makes no distinction between physical and virtual CPU. In essence, it means that a license must be purchased for every single virtual machine where the software is made available, and this is a problem for the IT group since they rely extensively on virtualization to accelerate the delivery of new software capabilities.
Initial approach
New systems and software capabilities are rolled out in the organization following a value stream project management approach.
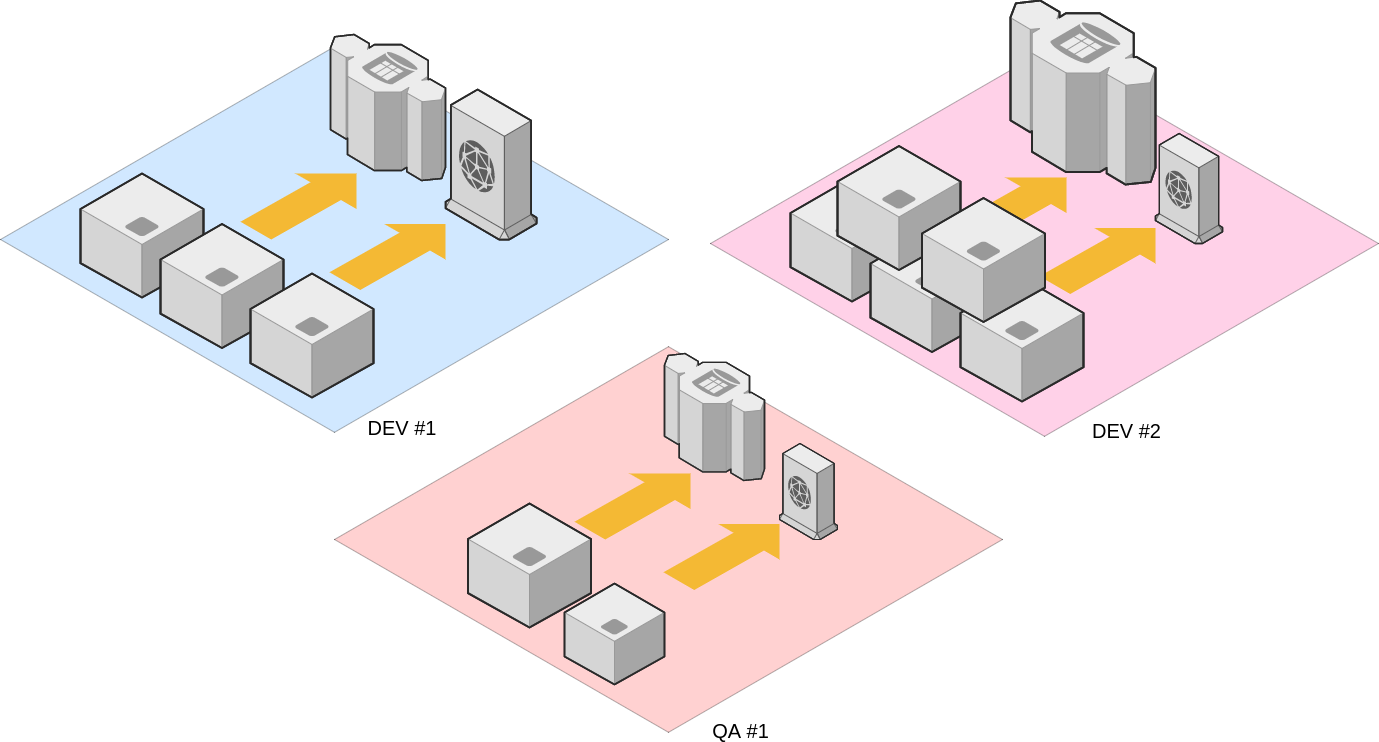
To enable work on multiple value streams at once, the IT group typically provisions many identical environments that are allocated to the various teams as needed. The process is quite fluid, relying on a mix of open-source and homegrown tools to manage the large inventory of virtual machines.
Each development environment is self-contained and self-sufficient. The size and specifications of the virtual machines can vary, depending on the needs of the team, but typical environments include the following:
- a cluster of application servers
- a dedicated database server
- a dedicated systems integration server
With the new systems integration platform, this approach is no longer cost-effective, as it requires an expensive license for every single development and QA environment, of which there are hundreds (and counting). Selecting a new integration platform is not an option either, so the IT group has to adapt its software development process.
Exploring new avenues
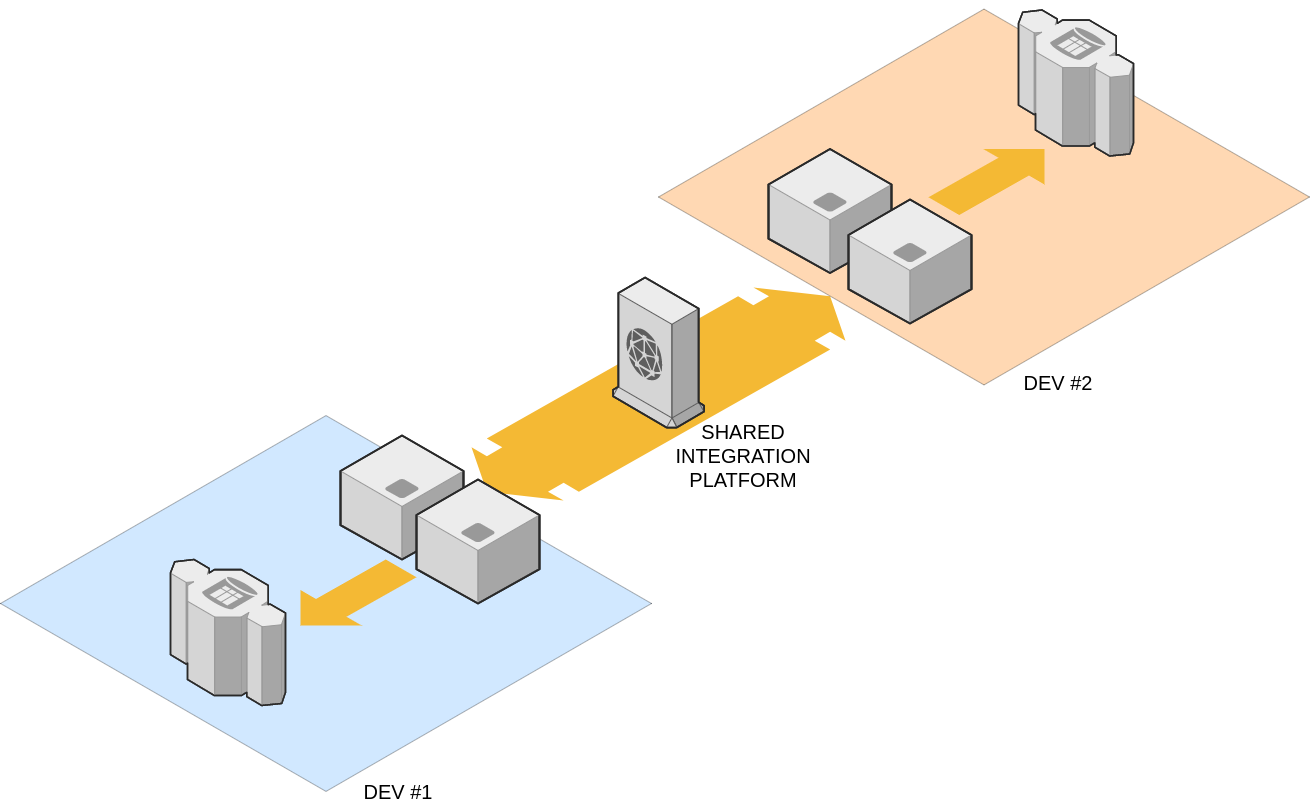
From a licensing perspective, it makes sense to have multiple development environments share a same instance of the integration platform. This approach, however, presents some technical challenges since the product is monolithic and doesn't handle configuration changes smoothly. If a same instance is shared by multiple teams, changes made by one team would disrupt the others.
To solve this problem, the team turns to the Docker container technology, which allows for a level of abstraction almost as complete as that of a virtual machine but without requiring a dedicated CPU. With Docker, the DevOps team is able to spin many instances of the integration platform on a single virtual machine, requiring a single license, while providing a decent level of isolation to many different teams.
The team looks carefully at system resources to determine the overall computing requirements, and finally rolls out a small cluster of virtual machines, each crammed with as many instances of the systems integration platform as possible. With this new approach, less than a dozen licenses are needed to support the flow of messages between thousands of virtual machines. It's a big win for the DevOps team and for the organization as a whole.
More moving parts, more problems
Implementing the shared integration platform is simple, but managing the overall inventory proves more difficult than expected. The DevOps team is used to self-contained environments but now has to consider shared assets.
The production integration layer includes hundreds of endpoints. With development teams working in parallel on various delivery schedules, some of the integration endpoints have four or five different versions used concurrently. This means that each instance of the integration platform could host hundreds or even thousands of web services at any given time.
To make matters worse, some integration endpoints require more computing power than others, which leads to asymmetrical performance: some instances of the integration platform are collapsing under the heavy load, while others are basically idle. The DevOps team soon finds itself playing a neverending game of Tetris, moving endpoints around, trying to find the sweet spot in a constantly changing ecosystem. Essentially, the inventory has turned from a simple tabular format to an undirected graph, and none of the existing tools are designed for this level of complexity.
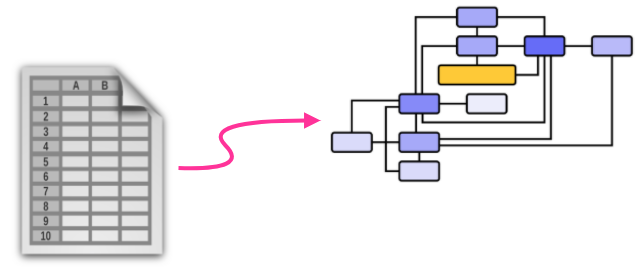
Rather than re-engineer its entire release and deployment system, the DevOps team opts for a time-tested approach: throwing hardware at the problem. They provision larger and larger virtual machines, up to the point where any single instance can host all the possible versions of all integration endpoints at the same time, relying on the hypervisor to deal with fluctuation in computing requirements. This more or less solves the performance problem, and brings the inventory back to a manageable tabular design - but with many, many rows.
Mapping and routing, ad nauseam
Manually updating the new inventory is a grueling task. For each development environment, someone has to configure the list of integration endpoints used by the various components. Since each instance of the integration platform hosts all the possible versions of all the endpoints, configuring an environment requires sibylline mapping rules, involving endless variations of IP addresses, port numbers and url patterns. This is a tedious and error-prone approach.
To make matters worse, high-availability is a hard requirement for some of the environments. This means that a load-balancer has to route requests to at least two instances of the integration platform, which adds an extra layer of manual mappings. The DevOps team is struggling to keep up with this increasingly complex ecosystem.
This is the point where the organization enlists our services.
Service discovery to the rescue
The DevOps team knows that automation is the answer to their problem. The only missing piece in their puzzle is the concept of service discovery. Rather than manually maintaining a list of endpoints, port numbers and url patterns, they need to implement a mechanism by which each endpoint registers itself in the inventory so it can be dynamically discovered by the development environments.
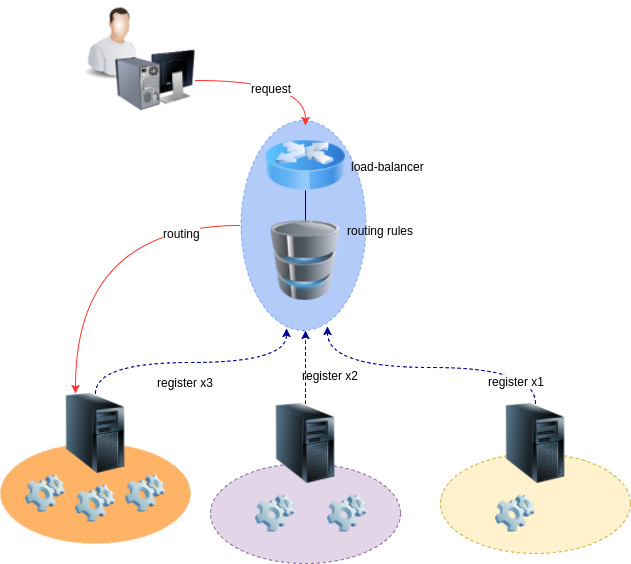
After experimenting with a scenario based on NGINX, the DevOps team finally opts for a Traefik/Consul solution to implement the service discovery layer.
How it works
- A developer creates a new version of an integration endpoint. The code is committed to source control (git).
- The build automation utility (Jenkins) pulls the code from source control and creates a new Docker image using that code. The name and version of this new Docker image is registered in Consul as a new frontend rule.
- A new Docker container is created on every instance of the integration platform using the new image. Each container registers itself as a new backend associated with the appropriate frontend.
- Traefik can route requests to the new endpoints.